Roofline¶
An overview of the roofline components can be found here.
In general, a roofline plot requires measuring two quantities (NOTE: MOI == metric-of-interest):
Performance: MOI per unit time, e.g. GFLOPs/sec
Arithmetic Intensity (AI): MOI per byte, e.g. FLOPs/byte
Generating Roofline Data¶
Assuming the code contains a tim::component::cpu_roofline<...>:
# execute and enable hardware counters for arithmetic intensity
TIMEMORY_ROOFLINE_MODE=ai ./test_cxx_roofline
# execute and enable hardware counters for operations
TIMEMORY_ROOFLINE_MODE=op ./test_cxx_roofline
Roofline Python Module: timemory.roofline¶
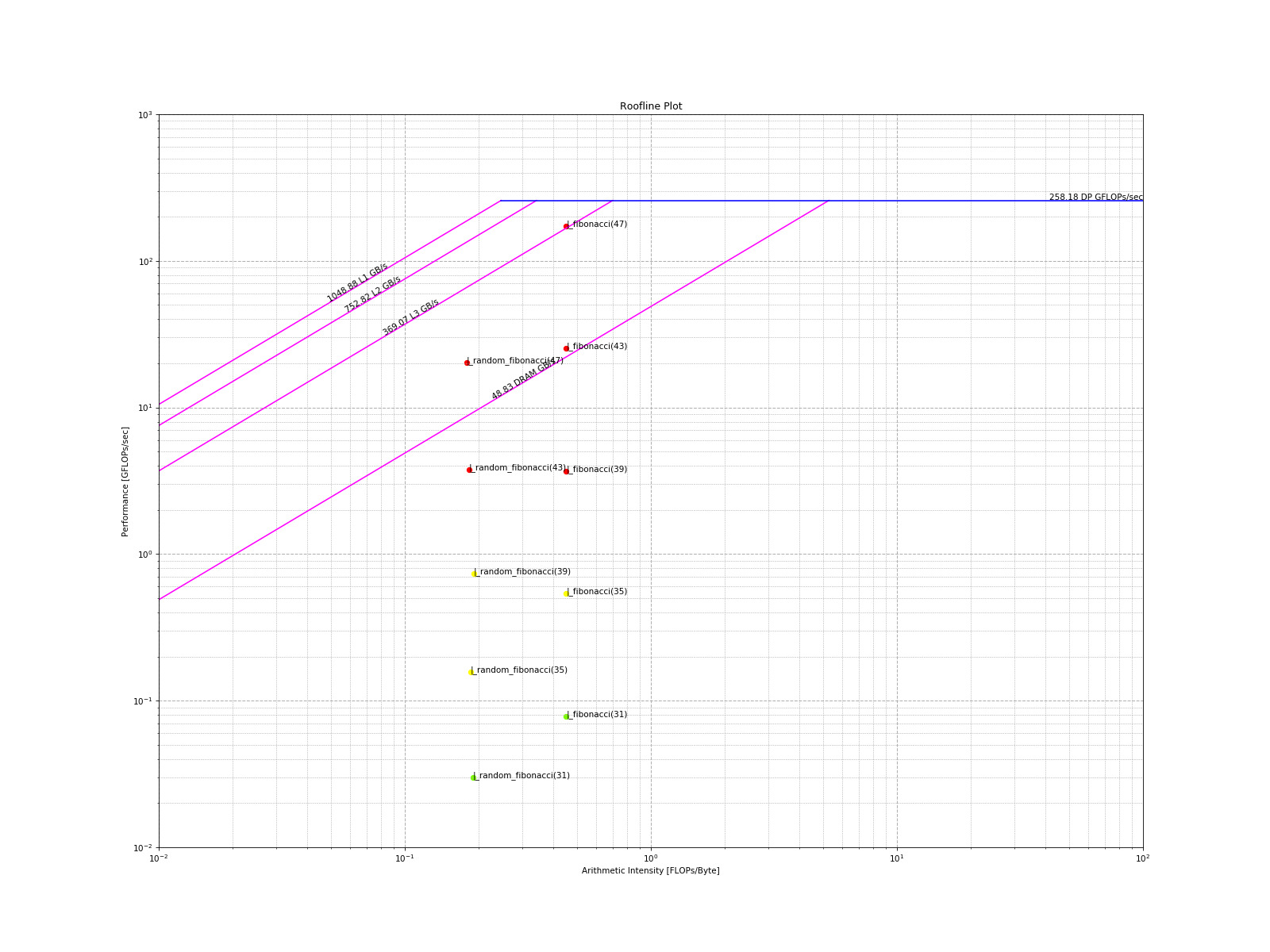
Generating Roofline Plot with timemory.roofline¶
Currently, some hardware counters cannot be accumulated in a single-pass and as a result, the application must be executed twice to generate a roofline plot:
python -m timemory.roofline \
-ai timemory-test-cxx-roofline-output/cpu_roofline_ai.json \
-op timemory-test-cxx-roofline-output/cpu_roofline_op.json \
-d
| Option | Type | Description |
|---|---|---|
-ai, --arithmetic-intensity |
File | Input JSON with AI data |
-op, --operations |
File | Input JSON with Operation data |
-d, --display |
bool | Open a window with the plot |
-o, --output-file |
String | Output filename of roofline plot |
-D, --output-dir |
String | Output directory for plot |
--format |
Image file suffix | Image format to render |
Executing an Application with timemory.roofline¶
python -m timemory.roofline -- ./test_cxx_roofline
| Option | Type | Description |
|---|---|---|
-k, --keep-going |
bool | Continue even if execution returned non-zero exit code |
-t, --rtype |
Label | Roofline type |
-r, --rerun |
ai, op |
Re-run this mode and not the other mode |
-d, --display |
bool | Open a window with the plot |
-o, --output-file |
bool | Output filename of roofline plot |
-D, --output-dir |
bool | Output directory for plot |
-n, --num-threads |
integer | Number of threads for the peak roofline calculation |
--format |
bool | Image format to render |
Customizing the calculation of the “roof” for the Roofline¶
Timemory will run a customizable set of calculations at the conclusion of the application of calculate these
peak (“roof”) values. This functionality is provided through the tim::policy::global_finalize
policy.
The default behavior of the roofline is targeted towards the multithreaded FMA
(fused-multiply-add) peak and calculates the bandwidth limitations for L1, L2, L3, and DRAM.
Configuring number of threads in the Roofline¶
| Environment Variable | Function |
|---|---|
TIMEMORY_ROOFLINE_NUM_THREADS |
std::function<uint64_t()>& get_finalize_threads_function() |
Example:
cpu_roofline_dp_flops::get_finalize_threads_function() = []() { return 1; };
Full Customization of the Roofline Model¶
Full customization of the roofline model can be accomplished through:
tim::ert::exec_data<T>which handles the execution measurementstim::ert::counter<DeviceT, T, DataT>which handles the accumulation of the execution measurementstim::ert::configuration<DeviceT, T, DataT>which handles the configuration data such as the number of threads, streams, alignment, etc.tim::ert::executor<DeviceT, T, DataT>which handles the algorithms and workflow of the
using Tp = double;
using device_t = tim::device::cpu;
using params_t = tim::ert::exec_params;
using wall_t = tim::component::wall_clock;
using data_t = tim::ert::exec_data<wall_t>;
using counter_t = tim::ert::counter<device_t, double, data_t>;
using config_t = tim::ert::configuration<device_t, double, data_t>;
using data_ptr_t = std::shared_ptr<counter_t>;
using roofline_t = tim::component::cpu_roofline<double>;
// sets up the configuration
config_t::get_executor() = [=](data_ptr_t data) {
// test getting the cache info
auto l1_size = tim::ert::cache_size::get<1>();
auto l2_size = tim::ert::cache_size::get<2>();
auto l3_size = tim::ert::cache_size::get<3>();
auto lm_size = tim::ert::cache_size::get_max();
auto dtype = tim::demangle<double>();
uint64_t max_size = 8 * lm_size;
uint64_t align_size = 64;
auto num_threads = config_t::get_num_threads()();
auto working_size = config_t::get_min_working_size()();
// log the cache info
std::cout << "[INFO]> L1 cache size: " << (l1_size / tim::units::kilobyte)
<< " KB, L2 cache size: " << (l2_size / tim::units::kilobyte)
<< " KB, L3 cache size: " << (l3_size / tim::units::kilobyte)
<< " KB, max cache size: " << (lm_size / tim::units::kilobyte)
<< " KB\n\n"
<< "[INFO]> num-threads : " << num_threads << "\n"
<< "[INFO]> min-working-set : " << working_size << " B\n"
<< "[INFO]> max-data-size : " << max_size << " B\n"
<< "[INFO]> alignment : " << align_size << "\n"
<< "[INFO]> data type : " << dtype << "\n"
<< std::endl;
params_t params(working_size, max_size, num_threads);
counter_t _counter(params, data, align_size);
return _counter;
};
// does the execution of ERT
auto callback = [=](counter_t& _counter) {
// these are the kernel functions we want to calculate the peaks with
auto store_func = [](double& a, const double& b) { a = b; };
auto add_func = [](double& a, const double& b, const double& c) { a = b + c; };
auto fma_func = [](double& a, const double& b, const double& c) { a = a * b + c; };
// set bytes per element
_counter.bytes_per_element = sizeof(double);
// set number of memory accesses per element from two functions
_counter.memory_accesses_per_element = 2;
// set the label
_counter.label = "scalar_add";
// run the operation _counter kernels
tim::ert::ops_main<1>(_counter, add_func, store_func);
// set the label
_counter.label = "vector_fma";
// run the kernels (<4> is ideal for avx, <8> is ideal for KNL)
tim::ert::ops_main<4, 8>(_counter, fma_func, store_func);
};
// set the callback
roofline_t::set_executor_callback<double>(callback);